author:魏静崎
2024年10月15日
Golang基础知识
注:来源于多篇博客、视频和自我总结等
基础
数组、切片、map
数组
- 数组里的元素必须全部为同一类型,要嘛全部是字符串,要嘛全部是整数
- 声明数组时,必须指定其长度或者大小,因此很少使用
- 如果要修改某个值,只能根据索引去找然后替换
- 在golang中,数组是值类型而不是引用类型
1
2
3
4
5// 初始化数组的方式
var array1 [3]int = [3]int{1, 2, 3}
var array2 = [3]int{4, 5, 6}
var array3 = [...]int{7, 8, 9} // ...是固定写法
var array4 = [...]int{1: 99, 0: 88, 2: 11} //下标: 值
切片
- 切片(Slice)相较于数组更灵活,因为在声明切片后其长度是可变的。
- 切片追加元素不影响切片本身,而是形成一个新的切片并返回
新的切片来自于一个新复制的扩容后的底层不可见数组,因此地址会发生改变 - 对数组的切片实际上是引用而不是值拷贝字符串也可以进行切片处理
1
func(slice) // 虽然func是值传递,但是slice是引用类型,因此传递的是slice的值也就是地址,因此外部的slice会改变
rune是int32的别名,在所有方面都等同于int321
2
3
4
5
6
7
8
9
10
11
12
13
14var str string = "hello cuc" // 字符串底层就是一个byte数组,因此可以切片处理
slice := str[:7]
fmt.Println(slice)
//str[0] = 'H' // 报错,因为string不可变,如果要修改,必须要转为byte或者rune数组然后切片修改,然后再转回字符串
byteSlice := ([]byte(str))[:] // 转为byte数组再切片
byteSlice[0] = byte('H')
str = string(byteSlice)
// 转成byte可以处理英文和数字,但是不能处理中文,原因是一个汉字三个byte,因此得转为rune处理
var chinese = "后天,有个不回消息的人生日"
byteSlice2 := ([]rune(chinese))[:] // 转为byte数组再切片
byteSlice2[2] = '会'
str = string(byteSlice2)
map
- map(映射、字典)是一种内置的数据结构,它是一个
无序的key-value对的集合
使用之前必须初始化,如make操作
但是println时会默认按照key的升序排列,for的时候依然无序1
2
3
4
5
6// 如果要对map排序,先将key转为slice,再对slice排序即可用key进行遍历
var mapSlice []int
for i, _ := range map1 {
mapSlice = append(mapSlice, i)
}
sort.Ints(mapSlice) // 对key进行排序 - map是引用类型,引用会直接修改其值
- map是会自动扩容的,无需像slice一样需要append
函数
匿名函数
1 | // 匿名函数在定义时就直接调用 |
闭包函数
返回的是一个匿名函数,但是这个匿名函数引用了函数外的变量n
因此这个匿名函数和引用的变量n形成了一个整体,构成闭包。
反复调用该函数时,n只初始化一次,因此每次调用就进行累计
1 | func add() func(int) int { |
defer
defer会暂时不执行,会压入到一个栈中,在当前资源(函数)被释放(结束)时再出栈执行
比如当前方法return之前执行
面向对象
继承
1 | type Student struct { |
如果结构体或匿名结构体有相同的字段或方法,则编译器采用就近访问原则,即优先访问结构体本身的字段或方法
接口
接口类型是引用类型,因此默认值是nil
1 | // 定义接口 |
方法也接受接口作为参数
只要是实现了USB接口(指的是实现了接口声明的所有方法)
通过usb参数调用接口方法
1 | type Computer struct {} |
接口本身不能实例化,但是可以指向一个实现了该接口的自定义类型的实例
1 | var s Stu = Stu{"jiajia", 24} |
断言
类型断言:接口是一般类型,不知道具体类型,使用类型断言可以将interface{}类型转换成具体的类型
进行类型断言时,要保证类型一致,否则会引发panic
一个不定参数且不定类型方法断言示例:
1 | func TypeJudge(items ...interface{}) { |
线程
协程
协程是轻量级线程,是逻辑上的线程,它与线程相比,更加轻量级,占用资源少,切换速度快,适合用于处理耗时的IO操作。
MPG模式:M: 主线程,P: 协程池,G: 协程
主线程负责调度协程,协程池负责创建和销毁协程,协程负责执行具体的任务。
如果需要主线程等待协程,需要使用 sync.WaitGroup{}
协程的特点:
- 协程是轻量级线程,占用资源少,切换速度快。
- 协程的调度由主线程负责,主线程可以创建、调度、销毁协程。
- 协程的调度是由操作系统完成的,因此,协程的切换不会引起线程的切换,因此,协程的调度效率很高。
- 协程的创建和销毁是自动完成的,不需要手动管理。
- 协程的通信机制是通过channel实现的。
1
go func() // 直接使用go+函数即可实现开启协程
管道
协程中的数据可以通过管道传递给其他协程or主线程
- channel的本质是一个数据结构-队列,数据是先进先出的 ,本身线程安全
- 通道底层实现是通过锁来保证并发安全的,每个通道都有一个锁和一个读写队列,只有一个协程能够获取到锁进行读写操作,其他协程则会被阻塞直到获得锁。
- 管道是有类型的,可以指定数据类型,默认为interface{},一般不建议使用interface{}
因为这样存入的数据是接口,取出的元素类型为interface{},需要类型断言 - 管道不能自动扩容,只能指定容量go为提供了select,用于异步的从多个channel里面去取数据(很像switch)
1
2
3
4
5
6
7
8
9
10
11var intChan chan type // 定义一个管道
intChan = make(chan type, 10) //声明一个容量为10的type类型的channel
intChan <- 99 // 向管道写入数据
var num1 = <-intChan // 从管道读取数据
// 在没有使用协程的情况下,如果channel中没有数据,则会报告deadlock,需要使用select来避免死锁
<-intChan // 可以这样取数据但不接收数据
for i := range intChan { // 遍历管道不能使用普通的for循环,而应该使用range循环
fmt.Println(i)
}1
for { select { case money := <-moneyChan1: moneyList = append(moneyList, money) case name := <-nameChan1: nameList = append(nameList, name) case <-doneChan: return } }
泛型
泛型函数
这样就可以使用多种不同的数据类型
1 | func add[T int | float64 | int32](a, b T) T { |
泛型切片
1 | type MySlice[T any] []T |
反射
如下:
1 | type Stu struct { |
通过反射修改其值 :
1 | func modifyIntValue(v interface{}) { |
GC垃圾回收
垃圾回收是由垃圾回收器以类似守护协程的方式在后台运作,按照既定的策略为用户回收那些不再被使用的对象,释放对应的内存空间 。
Golang中的垃圾回收:并发三色标记法+混合写屏障机制
V 1.3: STW
Golang 1.5版本之前,go runtime在一定条件下(内存超过阈值或定期如2min),暂停所有任务的执行,进行mark(标记)和sweep(清扫)操作,操作完成后启动所有任务的执行。在内存使用较多的场景下,go程序在进行垃圾回收时会发生非常明显的卡顿现象。
标记:标记出当前还存活的对象
清扫:清扫掉未被标记到的垃圾对象
不足:没有调整可用内存的位置,因此会产生内存碎片,倘若有大对象需要分配内存可能导致分配失败。
改进:标记压缩算法:清扫时对存活对象进行压缩整合。
缺陷:压缩算法复杂度可能会很高。
半空间复制
半空间复制Semispace Copy在Java的JVM的垃圾回收中很常用,是用空间换时间。
分配两片大小相等的空间,称为fromspace和tospace。
每轮只使用fromspace,以GC作为轮次划分。
GC时,将fromspace中的存活对象转移到tospace,并对空间进行压缩整合。
GC后交换二者,开启新的一轮。
缺点:浪费空间
三色标记法
由迪杰斯特拉提出的,对象标记使用黑、灰、白三种颜色。
黑色:对象自身存活,且其指向对象已经标记完成。
灰色:对象自身存活,但其指向对象还未标记完成。
白色:对象尚未被标记到,可能是垃圾对象。
- 标记开始前,将根对象(全局对象、栈上局部变量)置黑,将其所指对象置灰。
- 标记规则是,从灰色对象出发,将其所指向的对象都置灰,所有指向对象都置灰后,当前灰对象置黑。
- 标记结束后,白色对象就是不可达的垃圾对象,需要进行清扫。
并发垃圾回收
1.5版本以来,Golang引入了并发垃圾回收机制,允许用户协程和后台的GC协程并发运行。
Golang垃圾回收可能存在漏标问题:漏标问题指的是在用户协程与GC协程并发执行的场景下,不分存活对象未被标记从而被误删的情况。例如:
- moment1:GC协程下,对象A被扫描完成,置黑;此时对象B是灰色,还未完成扫描
- momen2:用户协程下,对象A建立指向对象C的引用
- moment3:用户协程下,对象B删除指向对象C的引用
- moment4:GC协程下,开始执行对对象B的扫描
在上述场景中,由于GC协程在B删除C的引用后才开始扫描B,因此无法到达C. 又因为A已经被置黑,不会再重复扫描,因此从扫描结果上看,C是不可达的.
然而事实上,C应该是存活的(被A引用),而GC结束后会因为C仍为白色,因此被GC误删.
漏标问题是无法接受,其引起的误删现象可能会导致程序出现致命的错误. 针对漏标问题,Golang 给出的解决方案是屏障机制的使用
Golang 并发垃圾回收可能存在多标问题:多标问题指的是在用户协程与GC协程并发执行的场景下,部分垃圾对象被误标记从而导致GC未按时将其回收的问题. 这一问题产生的过程如下:
- 条件:初始时刻,对象A持有对象B的引用
- moment1:GC协程下,对象A被扫描完成,置黑;对象B被对象A引用,因此被置灰
- momen2:用户协程下,对象A删除指向对象B的引用
上述场景引发的问题是,在事实上,B在被A删除引用后,已成为垃圾对象,但由于其事先已被置灰,因此最终会更新为黑色,不会被GC删除.
错标问题对比于漏标问题而言,是相对可以接受的. 其导致本该被删但仍侥幸存活的对象被称为“浮动垃圾”,至多到下一轮GC,这部分对象就会被GC回收,因此错误可以得到弥补.
- Golang 垃圾回收如何解决内存碎片问题?
Golang采用 TCMalloc 机制,依据对象的大小将其归属为到事先划分好的spanClass当中,这样能够消解外部碎片的问题,将问题限制在相对可控的内部碎片当中.
基于此,Golang选择采用实现上更为简单的标记清扫算法,避免使用复杂度更高的标记压缩算法,因为在 TCMalloc 框架下,后者带来的优势已经不再明显.
- Golang为什么不选择分代垃圾回收机制?
分代算法指的是,将对象分为年轻代和老年代两部分(或者更多),采用不同的GC策略进行分类管理. 分代GC算法有效的前提是,绝大多数年轻代对象都是朝生夕死,拥有更高的GC回收率,因此适合采用特别的策略进行处理.
然而Golang中存在内存逃逸机制,会在编译过程中将生命周期更长的对象转移到堆中,将生命周期短的对象分配在栈上,并以栈为单位对这部分对象进行回收.
综上,内存逃逸机制减弱了分代算法对Golang GC所带来的优势,考虑分代算法需要产生额外的成本(如不同年代的规则映射、状态管理以及额外的写屏障),Golang 选择不采用分代GC算法.
屏障机制
漏标问题的本质就是,一个已经扫描完成的黑对象指向了一个被灰\白对象删除引用的白色对象。
一套用于解决漏标问题的方法论称之为强弱三色不变式:
- 强三色不变式:白色对象不能被黑色对象直接引用(直接破坏(1)),实际上是如果黑色对象要执行白色对象,则将该白色对象改为灰色
- 弱三色不变式:白色对象可以被黑色对象引用,但要从某个灰对象出发仍然可达该白对象(间接破坏了(1)、(2)的联动)
插入写屏障
屏障机制类似于一个回调保护机制,指的是在完成某个特定动作前,会先完成屏障成设置的内容.
插入写屏障(Dijkstra)的目标是实现强三色不变式,保证当一个黑色对象指向一个白色对象前,会先触发屏障将白色对象置为灰色,再建立引用.
删除写屏障
删除写屏障(Yuasa barrier)的目标是实现弱三色不变式,保证当一个白色对象即将被上游删除引用前,会触发屏障将其置灰,之后再删除上游指向其的引用.
混合写屏障
然而真实场景中,需要补充一个新的设定——屏障机制无法作用于栈对象.
这是因为栈对象可能涉及频繁的轻量操作,倘若这些高频度操作都需要一一触发屏障机制,那么所带来的成本将是无法接受的.
在这一背景下,单独看插入写屏障或删除写屏障,都无法真正解决漏标问题,除非我们引入额外的Stop the world(STW)阶段,对栈对象的处理进行兜底。
为了消除这个额外的 STW 成本,Golang 1.8 引入了混合写屏障机制,可以视为糅合了插入写屏障+删除写屏障的加强版本,要点如下:
- GC 开始前,以栈为单位分批扫描,将栈中所有对象置黑,其子对象置为灰色
- GC 期间,栈上新创建对象直接置黑
- 堆对象正常启用插入写屏障
- 堆对象正常启用删除写屏障
GO调度器GMP
多线程、多进程的问题?
1. 设计变得复杂
1. 数量越多,切换成本越大,也就越浪费
2. 资源冲突多
2. 多进程、多线程的壁垒
1. 占用内存多
2. 高CPU调度消耗
M:N的协程可以利用多核,但是非常依赖协程调度器的优化和算法
Goroutine的优化:一个goroutine默认只有4kb、调度灵活。
早期的Go调度器:利用基本的全局Go队列和比较传统的轮询利用多个thread去调度
GMP简介
G、M、P分别代表Goroutine、Thread、Processor。
全局队列:存放等待运行的G。
P的本地队列:
用于存放等待运行的G。
数量限制,不超过256G。
优先将新创建的G放在P的本地队列中,如果满了会放在全局队列中。
P列表:程序启动时创建,最多有GOMAXPROCS个
M列表:当前操作系统分配到当前Go程序的内核线程数
设计策略
- 复用线程:避免频繁的创建、销毁线程,而是对线程进行复用
- work stealing机制:当本线程无可运行的G时,尝试从其他线程绑定的P偷取G,而不是销毁线程。
- hand off机制:当本线程因为G进行系统调用阻塞时,线程释放绑定的P,把P转移给其他空闲的线程执行。
- 利用并行
GOMAXPROCS设置P的数量,最多有GOMAXPROCS个线程分布在多个CPU上同时运行。GOMAXPROCS也限制了并发的程度,比如GOMAXPROCS = 核数/2,则最多利用了一半的CPU核进行并行。 - 抢占
在coroutine中要等待一个协程主动让出CPU才执行下一个协程,在Go中,一个goroutine最多占用CPU 10ms,防止其他goroutine被饿死,这就是goroutine不同于coroutine的一个地方。 - 全局G队列
在新的调度器中依然有全局G队列,当P的本地队列为空时,优先从全局队列获取,如果全局队列为空时则通过work stealing机制从其他P的本地队列偷取G。
go func()经历了什么过程
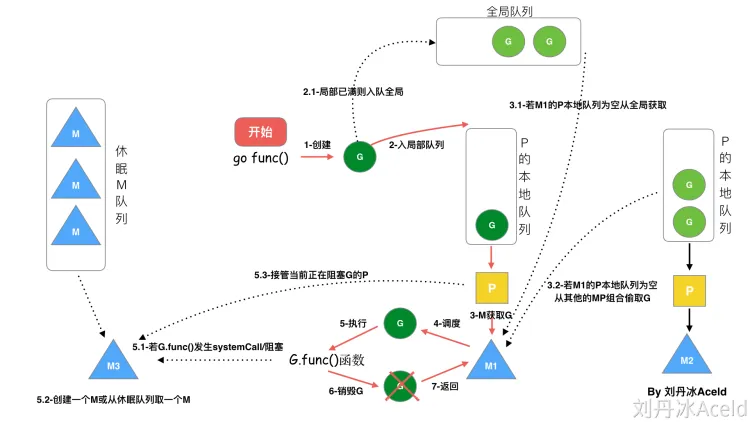
1、我们通过 go func()来创建一个goroutine;
2、有两个存储G的队列,一个是局部调度器P的本地队列、一个是全局G队列。新创建的G会先保存在P的本地队列中,如果P的本地队列已经满了就会保存在全局的队列中;
3、G只能运行在M中,一个M必须持有一个P,M与P是1:1的关系。M会从P的本地队列弹出一个可执行状态的G来执行,如果P的本地队列为空,就会想其他的MP组合偷取一个可执行的G来执行;
4、一个M调度G执行的过程是一个循环机制;
5、当M执行某一个G时候如果发生了syscall或则其余阻塞操作,M会阻塞,如果当前有一些G在执行,runtime会把这个线程M从P中摘除(detach),然后再创建一个新的操作系统的线程(如果有空闲的线程可用就复用空闲线程)来服务于这个P;
6、当M系统调用结束时候,这个G会尝试获取一个空闲的P执行,并放入到这个P的本地队列。如果获取不到P,那么这个线程M变成休眠状态, 加入到空闲线程中,然后这个G会被放入全局队列中。
调度器的生命周期
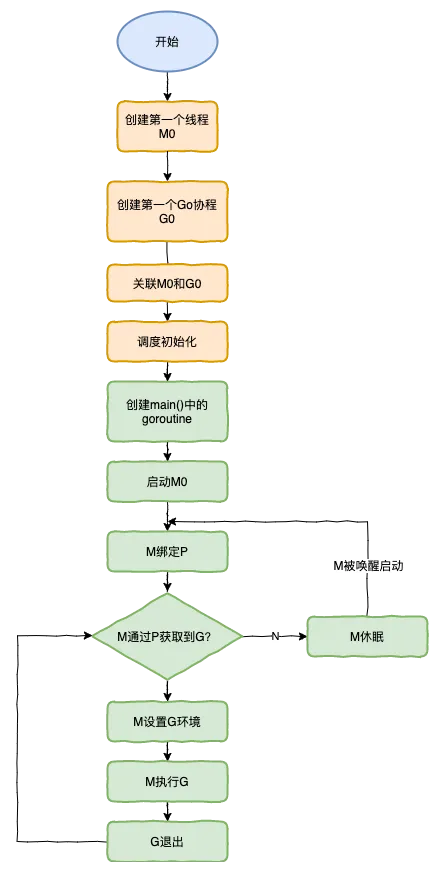
特殊的M0和G0:
M0是启动程序后的编号为0的主线程,这个M对应的实例会在全局变量runtime.m0中,不需要在heap上分配,M0负责执行初始化操作和启动第一个G, 在之后M0就和其他的M一样了。
G0是每次启动一个M都会第一个创建的gourtine,G0仅用于负责调度的G,G0不指向任何可执行的函数, 每个M都会有一个自己的G0。在调度或系统调用时会使用G0的栈空间, 全局变量的G0是M0的G0。


- 本文作者: 魏静崎
- 本文链接: https://slightwjq.github.io/2024/10/15/Go基础/
- 版权声明: 该文章来源及最终解释权归作者所有